AI / ML オフロード エンジン向け MEMSタイミング
| デバイス | 主な特徴 | 重要な価値 |
|---|---|---|
ネットワークシンクロナイザー SiT95148 1~220MHz |
|
|
スーパーTCXO SiT5501 [2] 1~60MHz |
|
|

[1] 12kHz~20MHzの積分範囲。 [2]より高い周波数についてはSiTimeにお問い合わせください。

オフロード エンジンは、高温で高密度になる可能性があるデータセンター環境でAI/ ML アプリケーションを高速化するために導入されるケースが増えています。SiTime MEMS 高精度タイミング ソリューションは、 AI/ ML ワークロードのクロックに必要な温度範囲でのパフォーマンスと安定性を実現します。当社のネットワーク シンクロナイザーは、複雑なアーキテクチャ向けに複数のクロック出力を提供します。当社のsuper TCXO は、急速な温度上昇と気流下でも優れたクロック安定性を提供します。
完全なMEMSクロックツリー高精度MEMSスーパーTCXO ネットワーク同期装置 | 実際の条件下でより堅牢正確なクロッキングのための dF/dT が 4 倍向上 気流と熱に強い 電源ノイズに対する耐性 | 薄型で使いやすいカバーやシールドなし カードの裏面にフィットする厚さ1mm以下 |
データセンター アプリケーションのAI/ML (人工知能 / 機械学習) ワークロードは、柔軟な FPGA ベースのサブシステムにオフロードされるケースが増えています。これらの FPGA ベースのAI/ML オフロード エンジンは、GPU ベースのシステムに比べて電力効率と計算効率に優れています。
オフロード エンジンは、非常に特殊な計算ニーズに対応する専用ハードウェア プラットフォームです。データセンターでは、 AI/ ML アプリケーションを高速化するためにオフロード エンジンの導入が進んでいます。クラウド コンピューティングにより、大規模なデータセットの集約が自然に可能になりました。データ分析を高速化したり、既存のデータの新しい用途を探したりするためにAIおよび ML 技術を採用する動きが加速し続けています。
SiTime ネットワーク シンクロナイザー製品は、高精度 TCXO および OCXO とともに、 AI/ML オフロード エンジンを導入するデータセンターで正確な時間管理を実現するための重要な技術です。
AI/ ML ワークロードは、Nvidia のグラフィック処理チップ (例) をベースにしたコンピューティング プラットフォームなどの専用ハードウェアを使用して効率的に処理できます。データセンターのもう 1 つのトレンドは、分散コンピューティングの採用です。大規模なワークロードは、複数の汎用 CPU (Intel または ARM) とローカル メモリを備えた HW ラックに分散されます。したがって、AIロードをスケジュールし、データセットの正確性と一貫性を維持するには、正確な時間管理が不可欠です。AI / ML オフロード エンジンは高価なリソースであり、これらのオフロード エンジンを高使用率にすることが、重要なシステム設計目標です。
| デバイス | 主な特徴 | 重要な価値 |
|---|---|---|
ネットワークシンクロナイザー SiT95148 1~220MHz |
|
|
スーパーTCXO SiT5501 [2] 1~60MHz |
|
|
[1] 12kHz~20MHzの積分範囲。 [2]より高い周波数についてはSiTimeにお問い合わせください。
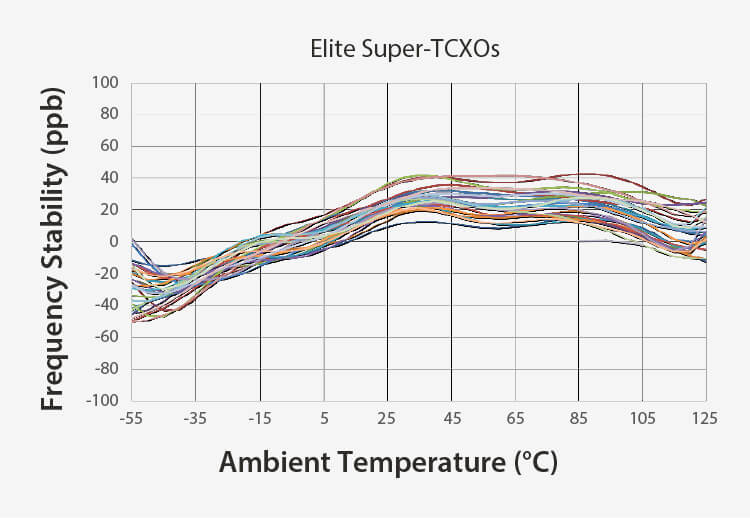
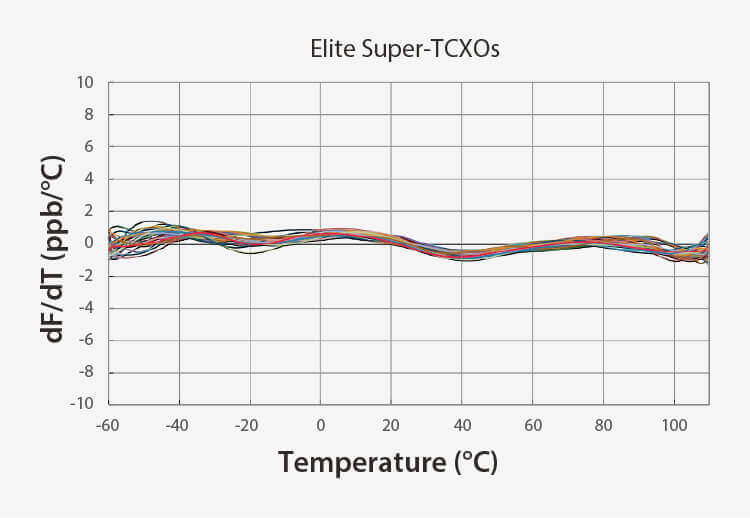
安定性の向上 | より良い周波数勾配 |
|---|---|
Image
| Image
|
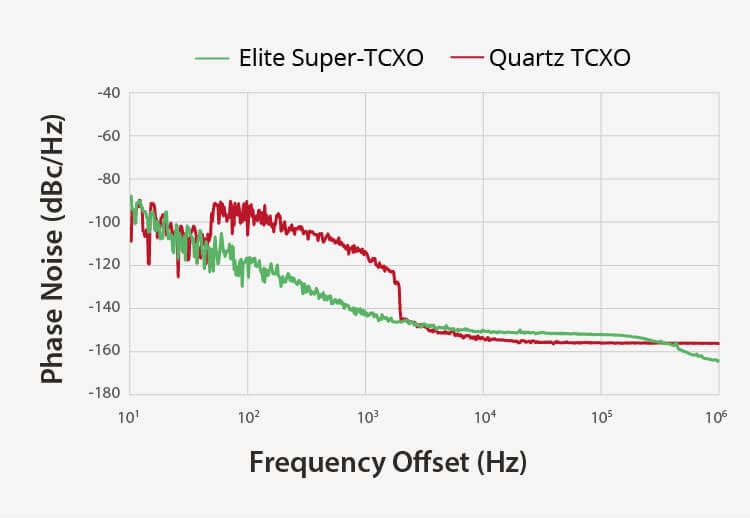
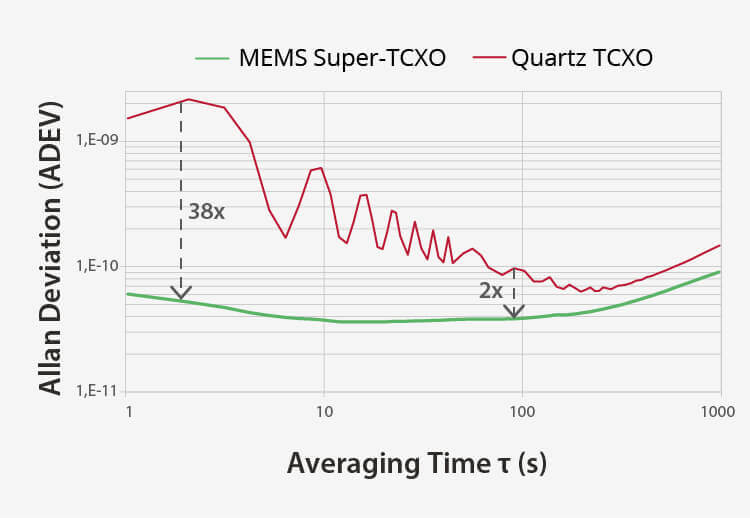
優れた耐振動性 | より良いアラン偏差 |
|---|---|
Image
| Image
|
