AI / ML オフロードエンジン向け MEMSタイミング
| デバイス | 主な特徴 | 主要な値 |
|---|---|---|
ネットワークシンクロナイザー SiT95148 1~220 MHz |
|
|
スーパーTCXO SiT5501 [2] 1~60MHz |
|
|

[1] 12kHz~20MHzの積分範囲; [2]より高い周波数についてはSiTimeにお問い合わせください

高温・高密度化が起こりやすいデータセンター環境において、 AI/MLアプリケーションの高速化を図るため、オフロードエンジンの導入がますます増加しています。SiTimeのMEMS高精度タイミングソリューションは、 AI/MLワークロードのクロックに必要な温度範囲における性能と安定性を提供します。当社のネットワークシンクロナイザーは、複雑なアーキテクチャ向けに複数のクロック出力を提供します。当社のsuper TCXOは、急激な温度上昇やエアフロー下でも優れたクロック安定性を提供します。
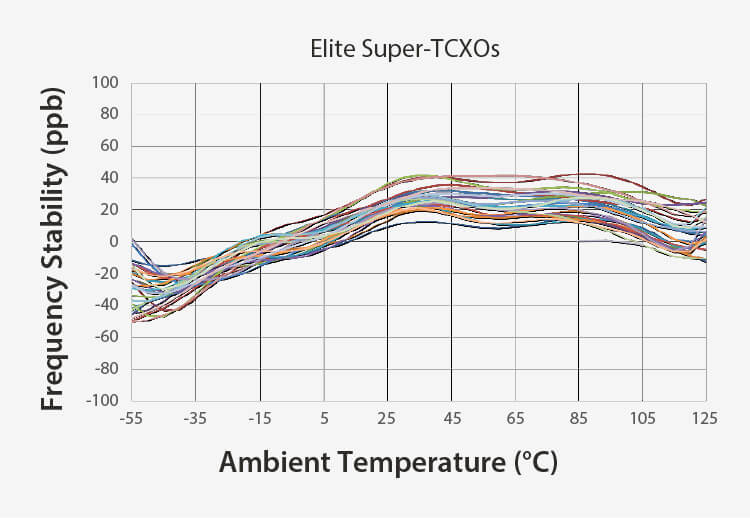
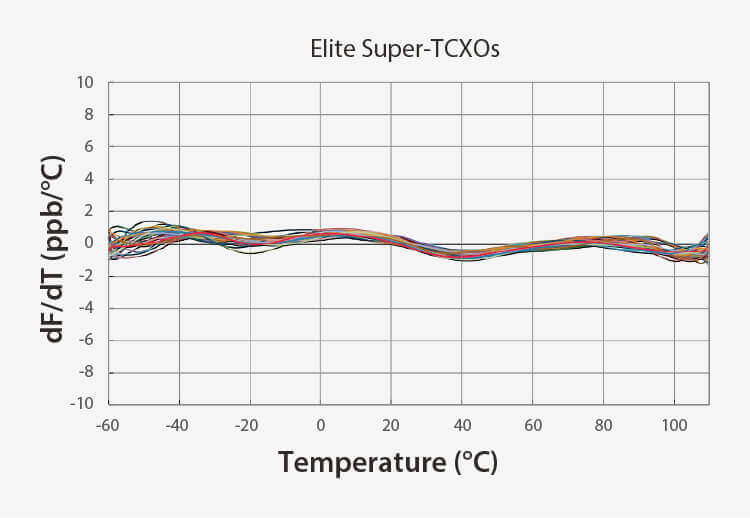
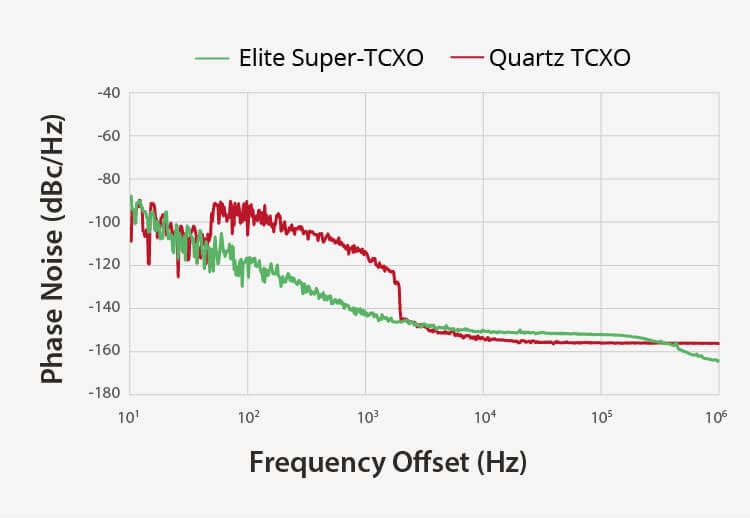
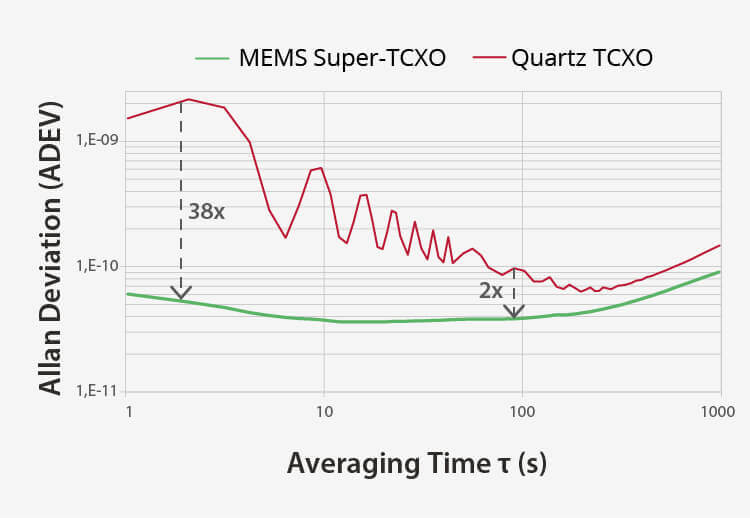
完全なMEMSクロックツリー高精度MEMSスーパーTCXO ネットワーク同期装置 | 実世界の条件でより堅牢正確なクロッキングのための dF/dT が 4 倍向上 通気性と熱に強い 電源ノイズに対する耐性 | 薄型で使いやすいカバーやシールドなし カードの裏面に収まる厚さ1mm以下 |
データセンター・アプリケーションにおけるAI/ ML(人工知能 / 機械学習)ワークロードは、柔軟なFPGAベースのサブシステムへのオフロードがますます増加しています。これらのFPGAベースのAI/ MLオフロードエンジンは、GPUベースのシステムと比較して、電力効率と計算効率に優れています。
オフロードエンジンは、非常に特殊な計算ニーズに対応する専用ハードウェアプラットフォームです。データセンターでは、 AI/ MLアプリケーションの高速化を目的として、オフロードエンジンの導入がますます進んでいます。クラウドコンピューティングは、大規模なデータセットの集約を自然に可能にしました。データ分析の高速化や既存データの新たな活用方法の模索を目的としたAIおよびML技術の導入は、加速を続けています。
SiTime ネットワーク同期製品は、高精度 TCXO および OCXO とともに、 AI/ML オフロード エンジンを導入するデータセンターで正確な時間管理を実現するための重要な技術です。
AI/ MLワークロードは、NVIDIAのグラフィック処理チップをベースにしたコンピューティングプラットフォームなどの専用ハードウェアによって効率的に処理できます(例:NVIDIA)。データセンターにおけるもう一つのトレンドは、分散コンピューティングの導入です。大規模なワークロードは、複数の汎用CPU(IntelまたはARM製)とローカルメモリを備えたハードウェアラックに分散されます。そのため、AIロードのスケジューリングとデータセットの正確性と一貫性の維持には、正確な時間管理が不可欠です。AI / MLオフロードエンジンは高価なリソースであり、これらのオフロードエンジンの高い利用率を確保することがシステム設計の重要な目標です。
| デバイス | 主な特徴 | 主要な値 |
|---|---|---|
ネットワークシンクロナイザー SiT95148 1~220 MHz |
|
|
スーパーTCXO SiT5501 [2] 1~60MHz |
|
|
[1] 12kHz~20MHzの積分範囲; [2]より高い周波数についてはSiTimeにお問い合わせください
優れた安定性 | より良い周波数勾配 |
|---|---|
Image
| Image
|
優れた耐振動性 | より良いアラン偏差 |
|---|---|
Image
| Image
|
